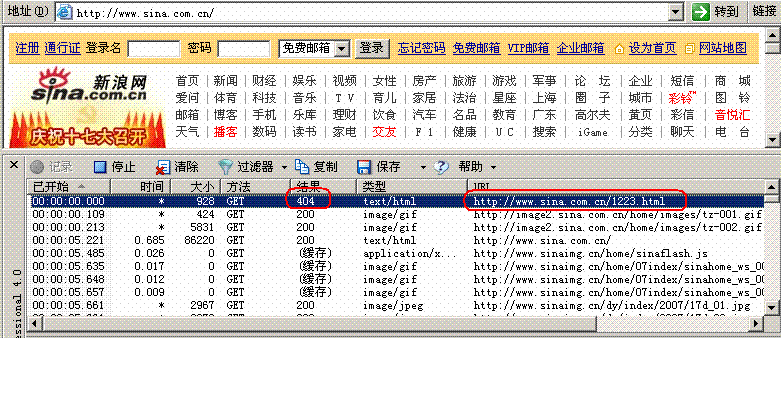
虽然大多数搜索引擎的蜘蛛程序现在基本都可以解读符号 “?”后的字符,但搜索引擎更喜欢静态文件,所以要对动态网页静态化。
在介绍静态化之前,介绍一些常用的正则表达式:
符号 匹配字符 示例
\d 任何十进制数字 等价
\D 任何非数字 等价
\s 任何空白字符 空格、制表符、分页符
\S 任何非空白字符 等价于 [^\f\n\r\t\v]
\w 任何单词字符 等价于 [A-Za-z0-9]
\W 任何非单词字符 等价于[^A-Za-z0-9]
\n 回车换行
. 除\n以外的任何字符 (.)+匹配除换行符以外的所有字符串
? 0个或1个前面的字符 ab?c?可以且只能匹配"abc"、"abbc"、"abcc"和"abbcc"
* 零个或多个所有的字符 ab*可以匹配"ab"、"abb"、"abbb"
+ 一个或多个所有字符 ab+可以匹配"abb"、"abbb"等,但不匹配"ab"
{n} n表示数量 如果是2,表示2个字符 a{2}可以匹配"aa"、但不匹配"a"
{n,n} 从几个字符开始到几个字符结束,如果不写表示至少或者至多
x|y 匹配"x"或"y"
\?\.\*\+ ?.*+
这里我介绍几种静态化方法:
1. 使用 IIS_ReWrite 静态化处理,适合 PHP、ASP、ASP.NET 程序。
A. isapi_rewrite.isapi_rewrite分精简(lite)和完全(full)版.精简版不支持对每个虚拟主机站点进行 重写,只能进行全局处理,精简版下载地址 ISAPI_Rewrite 2.7 For IIS 。
B. 打开 IIS,选择网站,右键菜单属性,添加过滤器。如图:
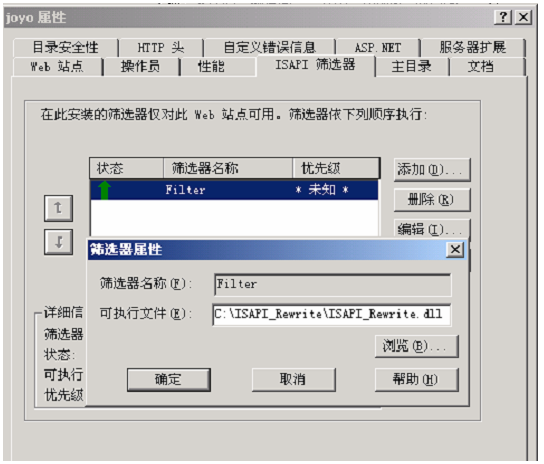
C. 打开文件:开始菜单->程序->Helicon->ISAPI_Rewrite->httpd.ini
D. 将 RewriteRule /user/(\d+).htm /user.asp\?id=$1 [I,O] 加入内容中。
E. 在浏览器地址栏输入:/user/1.htm 页面将指向 /user.asp?id=1。
2. 使用虚拟主机的 ASP 网站,需要使用 404 错误操作实现静态化。 404_Rewrite_GB2312.rar
A. 下载 404 处理页面。
B. 解压后将 Rewrite.asp、 error.asp 放在网站的根目录。
C. 设置网站自定义错误信息如图:
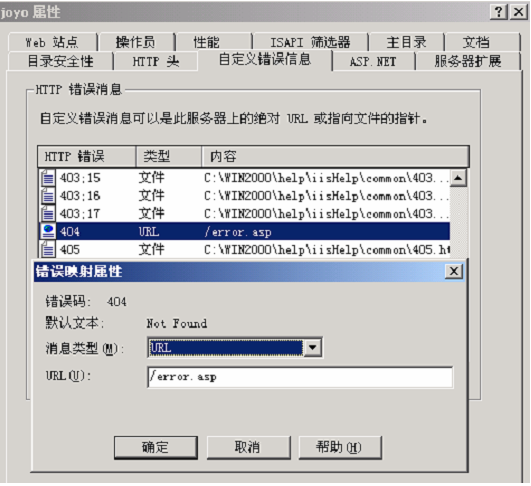
D. 在 error.asp 里添加处理命令:
Call ParaseUrl("/(\d+).htm","/user.asp?User=$1")
E. 在需要静态化的实例 user.asp 页面中添加代码:
<!-- #include virtual="/rewrite.asp" --> 引用文件
<%
response.write "<li>Para=" & session("Para") ‘变量是通过 Session 传递 ‘原来使用 request(“user”)获得参数的命令,需要修改成 request_(“user”)调用
response.write "<li>request_(""User"")=" & request_("User") ‘原用 request.querystring (“user”)获得参数命令,修改为 request__.querystring (“user”)调用
response.write "<li>request__.querystring(""User"")=" & request__.querystring("User")
%>
F. 在地址栏输入/1.htm ,实际调用 /user.asp?user=1
3. 使用 asp.net 开发的网页程序,使用 URLRewriter.dll 实现静态化。
1. 下载 URLRewriter.rar,解压后放在/bin/目录下
2. 将 URLRewriter.rar 加入工程引用。
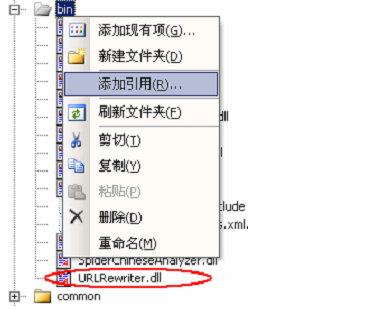
3. 配置 IIS 站点 ,将扩展名为 html 指向处理程序 aspnet_isapi.dll。 IIS 站点->属性->主目录->配置->添加 特别注意,一定不要选择 检查文件是否存在。
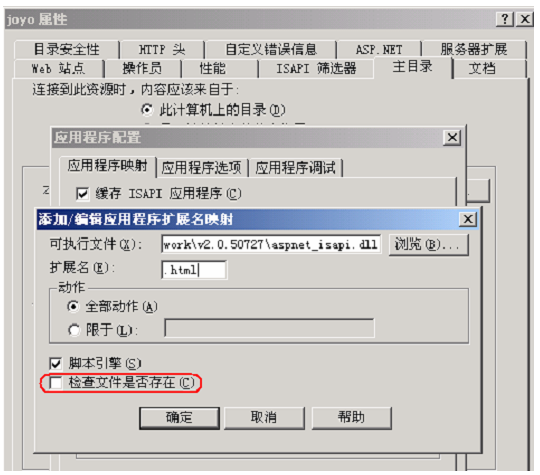
可执行文件和 aspx 处理相同,都是
c:\windows\microsoft.net\framework\v2.0.50727\aspnet_isapi.dll
4. 在 web.config 中添加配置内容,压缩包里有。
<configSections>
<section name="RewriterConfig"
type="URLRewriter.Config.RewriterConfigSerializerSectionHandler, URLRewriter" />
</configSections>
<!-- 实际重定向 -->
<RewriterConfig>
<Rules>
<RewriterRule>
<LookFor>~/(\d*).html</LookFor>
<SendTo>~/user/default.aspx?link=$1</SendTo>
</RewriterRule>
</Rules>
</RewriterConfig>
<system.web>
<!--
需要在 IIS 里面增加 html 引用,改成 aspx 的引用
-->
<httpHandlers>
<add verb="*" path="*.aspx"
type="URLRewriter.RewriterFactoryHandler, URLRewriter" />
<add verb="*" path="*.html"
type="URLRewriter.RewriterFactoryHandler, URLRewriter" />
</httpHandlers>
5. 在地址栏输入 http://localhost/1.html 指向 http://localhost/user/default.aspx?link=1
4. 基于 Apache HTTP Server 静态化
Apache Web Server 的配置 (conf/httpd.conf )
1. 在 httpd.conf文件中查找 LoadModule rewrite_module modules/mod_rewrite.so
通常该行被注释,去掉“#”。如果没有就增加该行。
2. 加入代码:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule ^/([0-9]+).html$ /user.php?user=$1
</IfModule>
3. 如果网站使用通过虚拟主机来定义,请务必将代码加到虚拟主机配置文件.htccess 中去,否
则可能无法使用。
4. 重启 Apache,重新载入配置。
5. 在地址栏输入 http://localhost/1.html ,实际指向 http://localhost/user.php?user=1
5. 静态化后文件格式
链接静态化后可以是 html 文件,也可以是目录,通常目录的权重大于文件的权重,可以在搜索
引擎中获得更好的排名。
http://www.supercss.com/user.asp?id=1
例如:优化前:
http://www.supercss.com/user/1.html
优化后 文件:
http://www.supercss.com/user/1/
目录:
http://www.supercss.com/user/1/ 有更高的优先权。
同等条件下
框架结构,即帧结构(Frame),包括IFrame,Frame。
框架结构示例。
例如:
<frameset rows="97,*" cols="*" frameborder="yes" border="0" framespacing="0">
<frame src="top.html" name="topFrame" frameborder="no" scrolling="No" noresize="noresize"
id="topFrame" title="topFrame" />
<frameset rows="*" cols="164,*" framespacing="0" frameborder="no" border="0">
<frame src="search_left/cat20.html?&catid=20&redirect=n" name="left"
frameborder="no" scrolling="yes" id="left" title="leftFrame" />
<frame src="CPU/cat20_list_1.html" name="main" id="main" scrolling="yes"
title="main">
</frameset>
</frameset>
<noframes>
在这里进行优化!
http://intozgc.com/CPU/cat20_list_1.html” title=” CPU报价”> CPU报价</a>
增加链接 <a href=”
</noframes>
框架型网站的优越性体现在页面的整体一致性和更新方便上。尤其对于那些大型网站而言, 框架结构的使用可以使网站的维护变得相对容易。但框架对搜索引擎来说是一个很大的问题,这是由于大多数搜索引擎都无法识别框架,也没有什么兴趣去抓取框架中的内容。此外, 某些浏览器也不支持
框架页面。 如果网页已经使用了框架,或出于某种原因一定要使用框架结构,则必须在代码中使用 “Noframes”标签进行优化,把 Noframe 标签看做是一个普通文本 <Noframe></Noframe>区域中包含指向 frame 页的链接以及带有关键词的描述文本 (title,meta)也出现关键词文本
还有一个办法是采用 iFrame既内联框架(Inner Frame)技术来避免Frame带来的不便.所谓ifame也是框架的一种形式,它是相当于在浏览器窗口中内嵌一个子窗口,内容自动打开,iframe 可以嵌在网页中的任意部分,也可以随意定义其代码显示为:
实例:<iframe src=www.25yi.com width=10 height=20 scrooling=0 frameborder=1></iframe>
对搜索引擎来说,iframe 中的文字是可见的,也可以跟踪到其中用户所见不同的是,搜索引擎将 iframe 内容看成单独的一个页面无关。